Table of contents
Intorduction
DOM Tree Terminology
What are Nodes?
Retrieve your document
Prepare your file using Tidy
DOM Returned values
Locating Nodes
Load document
A single element example
A list of elements example
XPath
XPath Conditions
XPath real example
Resources
Introduction
To scrape data from a website you will need to look first into the website API if it will satisfy your needs, so use it to get the data you need, if you want to extract data not available through the website’s API, so it’s the time to roll your sleeves to write your own tiny script to extract what you want.
If you know how to program in PHP it won’t be hard to use it to extract data from any website, in this tutorial I will not explain how to build a scraper, I will show you how to use the DOM and XPath together with PHP to navigate and extract the date you need.
DOM Tree Terminology
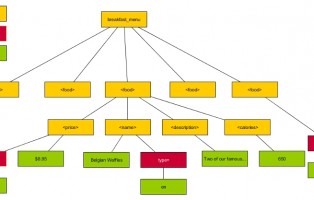
The Document Object Model (DOM) is a tree model structure for any given XML and HTML document, is like a family tree composed of nodes, each individual node can have child nodes
let’s take a look into the following xml example:
<breakfast> <food id="1"> <name type="en">Belgian Waffles</name> <price currency="usd">$8.95</price> <description>Two of our famous Belgian Waffles with plenty of real maple syrup</description> <calories>650</calories> </food> <food id="2"> <name type="en">Strawberry Belgian Waffles</name> <price currency="usd">$9.95</price> <description>Light Belgian waffles covered with strawberries and whipped cream</description> <calories>800</calories> </food> <food> <name type="en">Berry-Berry Belgian Waffles</name> <price currency="usd">$8.95</price> <description>Light Belgian waffles covered with an assortment of fresh berries and whipped cream</description> <calories>900</calories> </food> <food> <name type="fr">French Toast</name> <price currency="usd">$8.50</price> <description>Thick slices made from our homemade sourdough bread</description> <calories>900</calories> </food> <food> <name type="fr">Homestyle Breakfast</name> <price currency="usd">$6.95</price> <description>Two eggs, bacon or sausage, toast, and our ever-popular hash browns</description> <calories>950</calories> </food> </breakfast>

This document consists of
- elements are in yellow color
- attributes are in red color
- node values are in green color
breakfast is the root node.
food is a child of the breakfast element
name is a child of the food eleemnt
price is next sibling of the name (they share the same parent)
name is the previous sibling of price (they share the same parent)
$6.95 is the node value of the price element ( aka tag)
What are Nodes ?
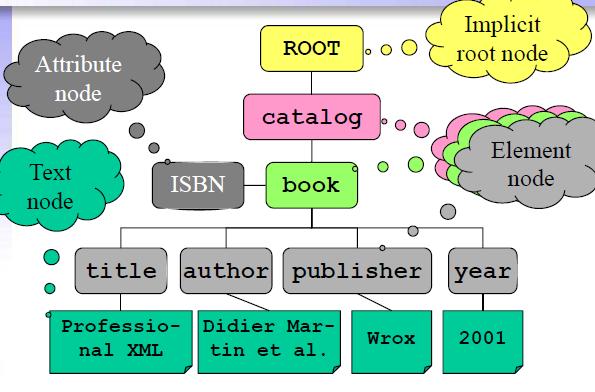
There are different types of nodes including:
elements nodes: they are of the form <tagname> and everything in between </tagname>
attributes nodes: they are attributes inside element tags: <tagname attribute=value>
text nodes: the text content of element tags, the text between <tagname> and </tagname>
for example:
<catalog> <book ISBN="1-861003-11-0"› <title>Professional XML</title> <author>Didier Martin et al.</author> <publisher>Wrox</publisher> <year>2000</year> </book> <book ISBN="0-596-52932-5"› <title>Programming Collective Intelligence</title> <author>Toby Segaran</author> <publisher>oreilly</publisher> <year>2007</year> </book> </catalog>
Retrieve your document
in PHP there are many ways to retrieve the document in which we will parse it there are some builtin functions like file_get_contents and you can use the cURL extension for this tutorial I will keep it simple and retrieve the documents using file_get_contents which works with http and https protocols.
$file = file_get_contents('https://raw.githubusercontent.com/abdul202/demos/master/dom_tree');
this will retrieve the contents of the webpage in the $file variable
Prepare your file using Tidy
at this point you have retrived the body of the document and it’s ready for parsing, in this phase we need to cleanup markups malformations, so you can use Tidy extension to handle this task for you i have created a function for this task
/**
*To tidy the html
*@param string $input_string raw HTML
*@param string $format xml or xhtml pass xml if you want to deal with xml leav it empty otherwise
*@return string "Cleans-up" (parsable) version raw HTML
*@since 4-11-2015
*/
function tidy_html($input_string, $format = 'html') {
if ($format == 'xml') {
$config = array(
'input-xml' => true,
'indent' => true,
'wrap' => 800
);
} else {
$config = array(
'output-html' => true,
'indent' => true,
'wrap' => 800
);
}
// Detect if Tidy is in configured
if( function_exists('tidy_get_release') ) {
$tidy = new tidy;
$tidy->parseString($input_string, $config, 'raw');
$tidy->cleanRepair();
$cleaned_html = tidy_get_output($tidy);
} else {
# Tidy not configured for this computer
$cleaned_html = $input_string;
}
return $cleaned_html;
}
This function will clean your document markups, it’s deafult input and the output is xhtml
$clean_doc = tidy_html($input_string);
$input_string, is your html or xml source if you dealing with xml document pass a second pramaeter as the follwing
$clean_doc = tidy_html($input_string, 'xml');
now you have retrieved the document and cleant it up it’s the time to extract the data we want from it
DOM Returned values
Each node we return has methods and properties in this tutorial i will focus only on which are frequently used in parsing.
- nodeName
- nodeValue
- getAttribute()
<price currency="usd">$9.95</price>
nodeName = price
nodeValue = $9.95
getAttribute(‘currency’) = usd
and if we return a nodelist it has a useful length property which holds the number of nodes returned, i will explain it later
Locating Nodes
In parsing routings we need to locate a single node or a list of nodes and the the DOMdocument class offer to 2 methods to help programmers to do that:
- getElementById() it will locate a single element with a certain id
- getElementsByTagName() it will locate a list of elements with a certain tag name
getElementsByTagName() method has useful length property to determine how many nodes in the list and return 0 if it’s empty, and the list is iterable as any other PHP aarray can be used in foreach loop
Load document
The DOMDocument class offers to methods to load the document:
- loadHTML — Load HTML source code
- loadHTMLFile — Load HTML from a file
The The DOMDocument class will emit warnings if the html page is not well formatted and this is something you don’t want to encounter, so first you pass the html code to the tidy function to clean it up if this doesn’t eliminate the problems, errors can be suppressed by this class method:
libxml_use_internal_errors(true);
An examples:
$source = file_get_contents("https://raw.githubusercontent.com/abdul202/demos/master/dom_tree"); //download the page
$file = 'page.html';
$doc = new DOMDocument;
// suppress errors
libxml_use_internal_errors(true);
// load the html source from a string
$doc->loadHTML($source);
// load the html source from a file
$doc->loadHTMLFile($file);
so far we have loaded the document to the DOMDocument object to parse it
A single element example
At this point i explain what the DOMdocument class load documents, locate nodes and its Returned values let’s put all this together
i will work on the xml example which at the beginning of this tutorial and you can find here in this link
https://raw.githubusercontent.com/abdul202/demos/master/dom_tree
in this example i want to extract the food element with all its child nodes with its full html markup
$source = file_get_contents("https://raw.githubusercontent.com/abdul202/demos/master/dom_tree"); //download the page
// claen the html using the tidy function
$clean_source = tidy_html($source, 'xml');
$doc = new DOMDocument;
// suppress errors
libxml_use_internal_errors(true);
// load the html source from a string
$doc->loadHTML($clean_source);
$element = $doc->getElementById('2');
// pass the $element as a prameter
$element_html = $doc->saveHTML($element);
echo $element_html;
the result:
<food id="2"> <name type="en">Strawberry Belgian Waffles</name> <price currency="usd">$9.95</price> <description>Light Belgian waffles covered with strawberries and whipped cream</description> <calories>800</calories> </food>
Note that i passed $element as a parameter for the saveHTML($element) to return the full html markup for just the node returned by getElementById() method, otherwise you will get the full page source instead
A list of elements example
in this example i want to extract all the foods names details
$source = file_get_contents("https://raw.githubusercontent.com/abdul202/demos/master/dom_tree"); //download the page
// claen the html using the tidy function
$clean_source = tidy_html($source, 'xml');
$doc = new DOMDocument;
// suppress errors
libxml_use_internal_errors(true);
// load the html source from a string
$doc->loadHTML($clean_source);
$nodelist = $doc->getElementsByTagName('name');
// the number of nodes in the list
$node_counts = $nodelist->length; // in our example it returns 5
if ($node_counts) { // it will be true if the count is more than 0
foreach ($nodelist as $node) {
echo $node->nodeName . ' => ' .$node->nodeValue .' => ' .$node->getattribute('type') .PHP_EOL;
}
}
The result
name => Belgian Waffles => en name => Strawberry Belgian Waffles => en name => Berry-Berry Belgian Waffles => en name => French Toast => fr name => Homestyle Breakfast => fr
The result explained
$node->nodeNam = name
$node->nodeValue = Belgian Waffles
$node->getattribute('type') = en
The $nodelist->length property is useful to check whether your script returned any number of nodes or not
in our previous example it will return 5 nodes because the <name> tag are 5
XPath
The XPath is a query language for selecting nodes from an XML or HTML document if you had never used it please there’s a great an overview about it in the resources section at the end of this tutorial
The XPath syntax is designed to mimic URL (Uniform Resource resources) and Unix-style file path syntax
in our prevouse xml example:
/breakfast/food/name
Returns a list of all name nodes for each food element in the breakfast.
another exaple to get all name nodes
//title
A single forward slash / it means it’s like a path to our nodes
A double forward slash // it means get all the nodes no matter where are they located in the document
XPath Conditions
Square brackets are used to delimit the conditional expression.
//food[@id = “2”]/name’
Returns all name nodes of the food node with an id of “2”
XPath real example
in thsi example i will extract a list of of New Movies titles In Theaters from the imdb from this link http://www.imdb.com/movies-in-theaters/
we need first to take a look into the page html source code you will find that each movie details is surrounded by a table and and the movie title is a link (a tag ) and surrounded by h4 tag with this attribute itemprop=”name”
<table>
<tbody>
<tr>
<td>
<div class="image">
image
</div>
</td>
<h4 itemprop="name">
<a href="/title/tt3707106/">
Movie title
</a>
</h4>
<div class="outline" itemprop="description">
Movie description
</div>
</tr>
</tbody>
</table>
So to build a XPath query to extract a list of all movie a tags
//table//h4[@itemprop="name"]//a
it will return all a tags which contain the titles to explain it in more details:
//table => get all tables nodes no matter where are they located in the doument
//h4[@itemprop="name"] => all h4 child nodes of the table with an itemprop of "name"
/a => all a child nodes of the h4 node
To extract all titles from this table here’s the code
$source = file_get_contents("http://www.imdb.com/movies-in-theaters"); //download the page
$clean_source = tidy_html($source);
$doc = new DOMDocument;
// suppress errors
libxml_use_internal_errors(true);
// load the html source from a string
$doc->loadHTML($source);
$xpath = new DOMXPath($doc);
$nodelist = $xpath->query('//table//h4[@itemprop="name"]//a');
$node_counts = $nodelist->length; // count how many nodes returned
if ($node_counts) { // it will be true if the count is more than 0
foreach ($nodelist as $element) {
echo $element->nodeValue . "\n";
}
}
The result:
By the Sea (2015) The 33 (2015) Love the Coopers (2015) Prem Ratan Dhan Payo (2015) James White (2015) Entertainment (2015) Je suis Ingrid (2015) My All American (2015) Kajaki (2014) Seul sur Mars (2015) Chair de poule (2015) Le pont des espions (2015) Hôtel Transylvanie 2 (2015) À vif! (2015) Le dernier chasseur de sorcières (2015) Paranormal Activity: The Ghost Dimension (2015) Our Brand Is Crisis (2015) Crimson Peak (2015) Steve Jobs (2015)
i hope i explained to you how to scrape some data using PHP DOMDocument and DOMXPath
Resources